
🔷 들어가며
안녕하세요. 이번 글에서는 B2B 쿠폰 솔루션인 굿폰 서비스를 개발하며 겪었던 선착순 쿠폰 발급의 성능 개선 과정과, 그로 인해 발생한 데이터 정합성 문제를 해결한 경험을 공유하려 합니다.
굿폰은 커머스 서비스를 운영하는 고객사가 자체 개발 없이도 손쉽게 쿠폰 및 프로모션 기능을 도입할 수 있도록 돕는 서비스입니다. 시스템은 크게 관리자용 Dashboard와 고객사 커머스 서비스 서버와 연동되는 Partner OpenAPI로 구성됩니다.
- Dashboard: 고객사 관리자가 계정과 상점을 생성하고, 쿠폰 템플릿 발행 및 관리하는 시스템입니다. 사용자별/주문별 쿠폰 내역을 조회하여 효율적인 운영을 지원합니다.
- Partner OpenAPI: 고객사의 커머스 서비스와 직접 연동되는 API 서버입니다. 최종 고객이 실제로 쿠폰을 발급받고, 조회하며, 사용할 수 있도록 지원합니다.
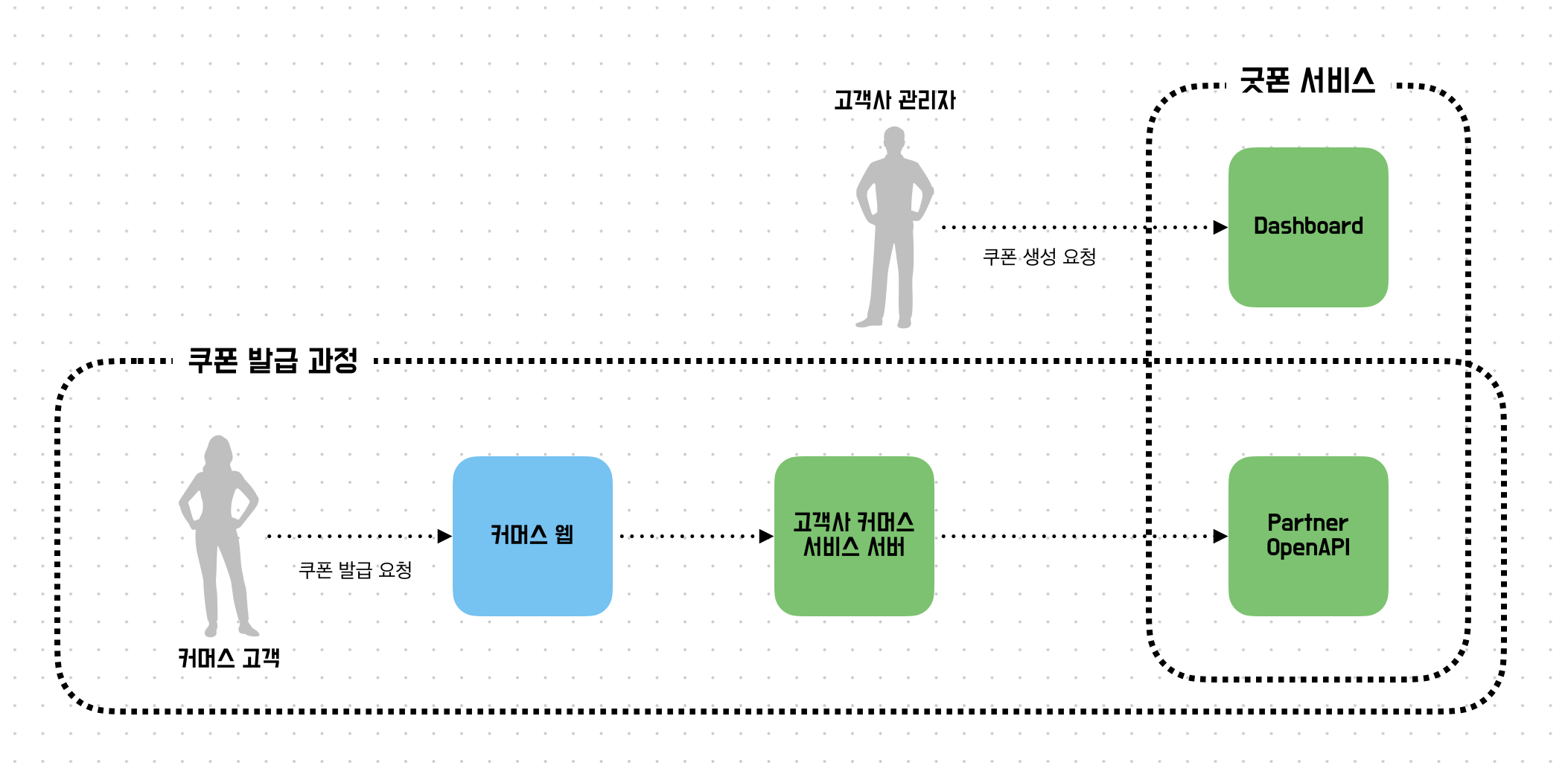
특히 Partner OpenAPI의 핵심인 선착순 쿠폰 발급 기능이 순간적인 트래픽이 몰리는 구간으로, 성능과 안정성을 위한 개선이 필요했습니다.
⚠️ 문제: DB 락의 병목
선착순 쿠폰 발급의 핵심은 정해진 수량을 초과하지 않도록 데이터 정합성을 보장하는 것입니다. 초기 아키텍처에서는 이를 위해 쿠폰 발급 수를 역정규화하여 쿠폰 통계 테이블로 분리하여 관리하고, 발급 요청 시 해당 레코드에 비관적 락을 거는 방식을 채택했습니다.
하지만 한계는 명확했습니다. OCPU 1, RAM 6GB 환경에서 K6를 이용해 동시 요청 1,000건에 대한 부하 테스트를 진행한 결과, P95 응답 시간이 6초 이상 지연되는 성능 저하가 발생했습니다.
정확한 원인 분석을 위해 Tempo로 트레이싱을 확인한 결과, 비즈니스 로직 수행 시간이 아닌 DB 락 획득을 위한 대기 구간이 전체 응답 시간의 대부분을 차지하고 있음을 확인했습니다.
🔷 개선: DB 락 제거와 Redis 활용
가장 먼저 DB 디스크 I/O와 락 경합으로 인한 병목을 해결하기 위해, 발급 수량 제어와 중복 검증 로직을 인메모리 저장소인 Redis로 이관했습니다.
1. Redis Lua Script를 활용한 원자적 검증
단순히 Redis 명령어를 여러 번 호출할 경우, 네트워크 왕복 시간이 발생하고 명령어 사이의 틈으로 인해 동시성 문제가 발생할 수 있습니다. 이를 해결하기 위해 Lua Script를 사용하여 검증과 발급 로직을 단 하나의 원자적 연산으로 묶었습니다.
동작 로직:
- SCARD: 현재 발급된 총개수를 조회하여 한도 초과 여부 확인.
- SISMEMBER: 해당 유저가 이미 발급받았는지 중복 여부 확인.
- SADD: 위 검증을 통과하면 유저 ID를 Set에 저장하고 true 반환.
- 실패 시 false 반환 (즉시 '수량 소진' 또는 '이미 발급됨' 응답).
RDBMS의 락 대신, 싱글 스레드로 동작하는 Redis의 특성과 Lua Script를 결합하여 락 대기 시간 없이 안전하고 빠른 검증이 가능해졌습니다.
2. 동기 처리 방식의 한계
하지만 Redis 도입만으로는 전체 처리량을 기대만큼 끌어올릴 수 없었습니다. 가장 큰 원인은 Redis 검증과 DB 저장 로직이 하나의 트랜잭션 안에서 동기적으로 묶여 있었기 때문입니다.
인메모리 기반인 Redis는 초당 수만 건 이상의 처리가 가능하지만, 디스크 I/O를 수행하는 DB는 그 속도를 따라갈 수 없습니다. 예를 들어, Redis 검증이 0.5ms 만에 끝나더라도, 이후 DB Insert 작업에 30ms가 소요된다면 해당 요청을 처리하는 톰캣 스레드는 총 30.5ms 동안 대기 상태가 됩니다. 즉, 앞단이 빨라져도 시스템의 전체 성능은 가장 느린 구간인 DB의 처리 속도에 맞춰지는 현상이 발생했습니다.
그렇다면 Spring의 @Async 등을 사용해 단순히 비동기로 처리하면 해결될까요? 이 역시 근본적인 해결책이 될 수 없었습니다. DB가 처리할 수 있는 속도는 정해져 있는데(예: 1,000 TPS), 앞단에서 Redis가 초당 10,000건씩 요청을 받아 넘겨버리면 서버 메모리 큐에 작업이 무한정 쌓이다가 메모리 부족 오류가 발생하거나, 서버 재시작 시 데이터가 유실되는 위험이 따르기 때문입니다.
🔷 개선: Kafka를 이용한 비동기 파이프라인
앞서 확인한 Redis(메모리)와 DB(디스크) 사이의 처리량 차이를 극복하고 안정성을 확보하기 위해, 두 시스템을 분리하고 그 사이에 Kafka를 배치했습니다. 이를 통해 선착순 검증과 최종 발급(DB 적재)의 책임을 명확히 나누는 지연 쓰기 전략(Write-Behind)을 적용했습니다.

1. 지연 쓰기 전략
대규모 트래픽을 처리하는 서비스들은 사용자가 버튼을 누르는 순간 모든 DB 처리를 완료하지 않습니다. 검증에 성공했으면 일단 성공 응답을 보내고, 실제 처리는 뒤에서 하는 접근 방식을 사용합니다. 저 또한 이 전략을 차용하여 프로세스를 재설계했습니다.
- API 서버: Redis Lua Script로 검증 및 발급 처리 (성공 시 즉시 Kafka 발행).
- 즉시 응답: 아직 DB에 저장되지 않았더라도, 사용자에게는 즉시 HTTP 200 OK를 반환.
- 후속 처리: 뒷단에서는 Consumer가 메시지를 가져와 DB에 INSERT 수행.
2. Consumer를 통한 유량 제어
이 구조의 핵심은 유량 제어입니다. 앞단에서 초당 1만 개의 요청이 유입되어도, Kafka가 이를 안정적으로 버퍼링 해줍니다. Consumer는 DB가 감당할 수 있는 속도(예: 초당 1,000개)로만 메시지를 가져와 처리하므로, 트래픽이 몰리는 상황에서도 DB 커넥션 풀이 고갈되거나 서버가 다운되는 것을 방지할 수 있습니다.
3. 파티션 키 전략을 통한 병렬 처리
Kafka의 처리량을 높이기 위해 파티션 키 설계에도 신경 썼습니다. 단순히 쿠폰 ID를 키로 사용하면 모든 요청이 하나의 파티션으로 몰리는 쏠림 현상이 발생합니다. 따라서 저는 사용자 ID를 파티션 키로 사용하여 메시지를 여러 파티션에 고르게 분산시켰습니다. 이를 통해 여러 대의 Consumer가 동시에 메시지를 처리할 수 있게 되어 전체 처리 성능을 높였습니다.
4. I/O 분리를 통한 처리량 개선
결과적으로 응답 속도에 가장 큰 병목이던 DB I/O가 사용자 응답 대기 시간에서 배제되었습니다.
- 변경 전 예시: Redis(1ms) + DB(30ms) = 31ms (대기)
- 변경 후 예시: Redis(1ms) + Kafka(3ms) = 4ms (즉시 응답)
톰캣 스레드가 요청을 붙들고 있는 시간이 줄어들면서, 동일한 서버 자원으로도 동시 처리량을 크게 개선할 수 있었습니다.
⚠️ 문제: Redis 쓰기 이후 메세지가 유실된다면?
Kafka를 도입하여 처리량은 개선되었지만, 데이터 정합성 측면에서 새로운 위험 요소가 발생했습니다. 바로 Redis와 Kafka 사이의 상태 불일치 문제입니다. Redis에서 수량 검증 및 발급 처리에는 성공했지만, Kafka로 메시지를 발행하기 직전에 서버가 다운되거나 네트워크 오류로 발행이 실패한다면 어떻게 될까요?
- Redis: 해당 유저를 '발급 완료'로 기록함. (재발급 불가)
- Kafka/DB: 메시지가 도달하지 않아 데이터가 없음.
결과적으로 유저는 "발급 성공" 응답을 받았지만, 실제로는 쿠폰이 발급되지 않는 유령 쿠폰 현상이 발생합니다. 이는 단순한 오류를 넘어, 사용자가 재시도를 해도 "이미 발급된 유저입니다"라는 응답을 받게 되므로 서비스 신뢰도에 영향을 줄 수 있는 문제입니다.
🔷 개선: Redis 2-Set 구조와 스케쥴러를 통한 정합성 보장
이 문제를 해결하기 위해 발급 상태를 진입과 확정 두 단계로 분리하여 관리하는 Redis 2-Set 전략을 도입했습니다.

1. 상태의 분리: RESERVED vs ISSUED
단일 Set으로 관리하던 발급 목록을 목적에 따라 두 가지 자료구조로 분리했습니다.
- RESERVED: 발급 요청이 들어와서 Kafka로 넘어가기 전의 임시 대기 상태입니다. ZSet(Sorted Set)을 사용하여 진입 시간을 기록하고 체류 시간을 추적합니다.
- ISSUED: Kafka를 거쳐 DB 저장까지 완료된 발급 확정 상태입니다. 일반 Set을 사용합니다.
2. 개선된 프로세스 흐름
- 진입 (API Server): Lua Script를 통해 RESERVED에 유저 ID와 타임스탬프를 등록합니다. 등록 성공 시 Kafka 메시지를 발행합니다.
- 확정 (Consumer): Consumer가 메시지를 읽어 DB 저장을 수행합니다. 저장이 완료되면 ISSUED에 유저를 추가하고, 동시에 RESERVED에서 제거합니다.
이 구조를 통해 RESERVED 영역에는 처리가 진행 중이거나, 문제가 생겨서 완료되지 못한 요청만 남게 됩니다.
3. 스케줄러를 통한 복구
이제 남은 것은 RESERVED 영역에 남아있는 '미아'들을 처리하는 것입니다. 별도의 배치 스케줄러가 주기적으로(예: 1분마다) 다음 로직을 수행하여 최종적 일관성을 보장합니다.
- 대상 조회: RESERVED에서 현재 시간보다 N분 이상 지난 요청들을 조회합니다.
- 검증 및 복구: 조회된 유저가 DB에 없다면 메시지 발행이 실패한 것으로 간주하여 Kafka 메시지를 재발행합니다.
⚠️ 문제 : Redis가 다운된다면 복구 시 정합성은?
여전히 해결해야 할 과제가 있었습니다. "만약 Redis가 다운되어 메모리 데이터가 유실된다면 어떻게 할 것인가?"였습니다.
이 경우 가장 큰 위험은 DB와 Kafka(처리 대기 중) 사이의 상태 불일치로 인한 수량 초과 발급 문제입니다.
1. 복구 시점의 수량 불일치
Redis가 재시작되었을 때, 단순히 DB에 있는 데이터를 Redis ISSUED Set으로 동기화한다고 가정해 봅시다.
- 상황: 선착순 100명 한정 이벤트에 현재 99명이 발급 완료된 상태입니다.
- Kafka 잔여 메시지: 100번째 당첨자인 User A의 메시지가 아직 Kafka에 남아있어 DB에는 반영되지 않았습니다.
- Redis 복구: DB에는 99명만 존재하므로, Redis는 현재 발급량을 99개로 복구합니다.
- 경쟁 조건: 이때 신규 유저 User B가 요청을 보냅니다. Redis는 "아직 1자리 남았다(99 < 100)"고 판단하여 User B의 진입을 허용합니다.
- 결과: Kafka에 있던 User A와 새로 들어온 User B가 모두 처리되면서 총 발급량이 101개가 되어 한도 초과 문제가 발생합니다.
DB의 유니크 키 덕분에 동일 유저의 중복 발급은 막을 수 있지만, 서로 다른 유저가 유입되어 총량을 넘기는 문제는 이처럼 단순 동기화로는 해결할 수 없습니다.
2. 플래그와 비우기 전략
이 문제를 해결하기 위해 불확실한 데이터를 모두 제거한 뒤 복구한다는 비우기(Drain) 전략을 수립했습니다. 이를 위해 Redis 상에 서비스 활성화 여부를 나타내는 플래그 키(예: EVENT_OPEN)를 두고, 이 키가 존재할 때만 발급을 허용하도록 설계했습니다.
- 플래그 소멸로 인한 입구 자동 차단: Redis가 재실행되면 메모리가 초기화되므로 플래그 키도 함께 소멸됩니다. 애플리케이션은 플래그 키가 없을 경우 발급 요청을 거부하도록 구현되어 있어, 별도의 수동 조치 없이도 장애 직후 신규 유입이 안전하게 차단됩니다.
- Kafka 비우기: 신규 진입이 막힌 상태에서, Kafka Consumer가 쌓여있는 잔여 메시지를 모두 처리할 때까지 대기합니다. 이 과정을 통해 처리 중인 데이터를 모두 DB에 저장하여 상태를 확정 짓습니다.
- 데이터 동기화: 모든 비동기 처리가 끝났으므로 이제 DB가 유일한 기준 데이터가 됩니다. DB에 저장된 발급 내역을 조회하여 Redis ISSUED Set에 다시 로드합니다.
- 서비스 재개: 동기화가 완료되면 Redis에 플래그 키를 다시 생성하여 정상 서비스를 재개합니다.
🔷 비교: 대기열 방식 (Redis Queue -> Scheduler -> DB)
대규모 트래픽 제어에 흔히 사용되는 대기열 방식도 검토했으나, 굿폰 서비스의 특성인 B2B2C 구조상 적합하지 않다고 판단했습니다.
1. 고객사의 구현 부담 가중
일반적인 B2C 서비스라면 대기열 순번을 SSE나 WebSocket을 통해 최종 유저에게 직접 전달할 수 있습니다. 하지만 굿폰은 [최종 유저 ↔ 고객사 커머스 서버 ↔ Partner OpenAPI] 구조를 가집니다.
만약 대기열 순번을 실시간으로 안내하려면, 굿폰이 고객사 서버로 Webhook을 보내고, 고객사 서버가 다시 유저에게 SSE로 중계해야 하는 복잡한 구조가 필요합니다. 이는 솔루션을 도입하는 고객사 개발팀에게 과도한 구현 부담을 전가한다고 생각했습니다.
2. 폴링으로 인한 고객사 서버 부하
대안으로 클라이언트가 주기적으로 순번을 확인하는 폴링 방식을 사용할 수 있습니다. 하지만 유저가 N초마다 대기 순번을 확인하기 위해 요청을 보낸다면, 이 요청은 반드시 고객사 서버를 거쳐서 우리에게 도달합니다.
즉, 우리 서비스의 트래픽 제어를 위해 고객사 서버에 불필요한 부하를 유발하게 됩니다. 이는 고객사 서비스의 안정성을 해칠 수 있어, 상생해야 하는 B2B 솔루션으로서 치명적인 단점이라고 생각했습니다.
3. 결론: 지연 쓰기의 선택
따라서 복잡한 대기열 UX를 강요하거나 고객사에 부담을 주는 대신, Redis의 빠른 처리 속도를 활용해 즉시 당락을 결정해주는 지연 쓰기 방식이 고객사와 최종 유저 모두에게 더 나은 경험을 제공한다고 결론 내렸습니다.
🔷 마치며
선착순 쿠폰 발급 로직을 개선하면서 모든 아키텍처에는 장단점이 존재하며, 완벽한 정답은 없다는 사실을 체감했습니다.
- DB 락: 데이터 정합성은 높지만, 성능과 확장성 측면에서 한계가 있었습니다.
- Redis + Kafka: 처리량은 크게 개선되었지만, 데이터 유실 가능성과 정합성 유지라는 새로운 과제를 안았습니다.
- 2-Set 구조 + 비우기 전략: 구현 복잡도는 높아졌지만, 성능과 안정성 사이의 균형을 맞출 수 있었습니다.
잘못된 부분이 있다면 댓글 남겨주시길 바랍니다. 읽어주셔서 감사합니다.
'서버' 카테고리의 다른 글
| Resilience4j CircuitBreaker, 직접 구현하면서 이해해보자! - 4편: 설정, 사용, Fallback (1) | 2025.11.21 |
|---|---|
| Resilience4j CircuitBreaker, 직접 구현하면서 이해해보자! - 3편: 슬라이딩 윈도우 (1) | 2025.11.21 |
| Resilience4j CircuitBreaker, 직접 구현하면서 이해해보자! - 2편: 상태 머신, 상태 전이 (0) | 2025.11.21 |
| Resilience4j CircuitBreaker, 직접 구현하면서 이해해보자! - 1편: 이해와 설계 (0) | 2025.11.21 |
| Redis 분산락, 직접 구현하면서 이해해보자! - 2편: Pub/Sub 방식 (0) | 2025.10.31 |