들어가며
프로젝트를 진행하면서 분산된 테크 스펙, 인프라, 정책들을 의사결정 기록(Decision Record)으로 통합하고, MCP 서버를 만들어 특정 시점에 어떤 결정을 했고 어떻게 변화해 왔는지를 빠르게 검색할 수 있도록 한 경험을 정리해보겠습니다. 구체적인 구현보다는 경험 위주의 글입니다.
문제 상황
현재 진행 중인 프로젝트에서 팀원이 개인 사정으로 잠시 자리를 비운 상태였습니다. 그 사이 한 달 간 AI Agent의 도움을 받아 총 600개의커밋, 2만 줄 가량의 코드를 작성했습니다. 팀원이 돌아올 시점이 되었을 때, 너무 많은 코드와 결정들이 쌓여 있어 부담스러운 상황이었습니다.
기존에는 GitHub에서 두 가지 방식으로 기록했습니다. Tech Spec은 GitHub Issue와 PR로 관리했고, 분야별 전체 고려 사항은 docs repository를 만들어 Git으로 누적해서 이력을 관리했습니다. Notion, Slack, Jira 같은 별도 도구 없이 GitHub에서 markdown 파일만 쓰는 구조였습니다.
문제는 이런 방식으로 쌓다 보니 이전 의사결정들을 찾기가 점점 어려워진다는 것이었습니다. Issue는 닫히면 흘러가버리고, docs repository의 누적 이력에서 특정 시점에 왜 그런 결정을 했는지 역으로 추적하기가 힘들었습니다. "구독/결제 솔루션을 선택한 이유", "메일 발송 정책을 왜 바꿨나" 같은 것들은 어딘가에 있긴 한데 정확히 어디 있는지 알 수 없는 상태였습니다. 게다가 인프라, 정책, 마케팅 관련 결정들은 Tech Spec에 들어갈 자리가 없어 머릿속에만 있고 누락되어 있었습니다.
그래서 문서 관리 방식을 바꾸기로 했습니다.
대응 1: 테크 스펙, 인프라, 기획, 정책들을 Decision Record로 통합
Tech Spec은 구현 레벨의 기술 결정만 담습니다. Decision Record는 개발, 인프라, 배포, 마케팅, 정책 등 프로젝트에서 일어나는 모든 결정을 아우를 수 있습니다. 팀원이 많지 않고 하는 일이 광범위했기 때문에, 기록 범위를 넓게 잡아도 괜찮다고 판단했습니다.
형식은 단순하게 유지했습니다. 각 파일은 YAML frontmatter로 날짜, 범위, 태그, 상태를 갖고, 본문에는 배경, 결정 사항, 트레이드오프, 후속 조치 등을 마크다운으로 작성하는 형식입니다. 각 Decision Record는 월별로 나누어 docs repository에 저장했습니다.
---
title:
description:
date:
author:
scope:
status:
tags: []
related: []
---
# 제목
## 배경
## 결정 사항
## (선택) 변경 사항
## (선택) 구현·운영
## (선택) 트레이드오프·리스크
## (선택) 후속 조치# docs repository
decision-records
ㄴ 2026-02
ㄴ 2026-02-01-Xxx.md
ㄴ ...
ㄴ 2026-03
ㄴ 2026-03-01-Xxx.md
ㄴ ...
ㄴ 2026-04
ㄴ 2026-04-01-Xxx.md대응 2: Github Issue, PR, Log 들을 Decision Record로 복원
형식을 정했으니 기존 기록들을 Decision Record 형식으로 변환해야 했는데, 수동으로 하기엔 양이 너무 많았습니다.
Copilot에게 각 repository별 Issue, PR, PR 코멘트를 읽게 하고, Decision Record 형식에 맞게 초안을 생성하도록 했습니다. 누락된 부분이 있을 수 있어서 Git 커밋 메시지도 함께 활용해 내용을 보완하도록 했습니다. 개발할 때 AI Agent를 통해 커밋 메시지를 자세하게 남겼던 것이 이 시점에 큰 도움이 됐습니다. 기획, 정책, 인프라, 배포 관련 정보들도 같은 방식으로 정리했습니다.
덕분에 20분 안에 모든 정보를 Decision Record로 마이그레이션할 수 있었습니다.
대응 3: Decision Records MCP로 검색 가능
기록을 한 곳에 모았지만, 이번엔 찾는 게 문제였습니다. LLM에게 자연어로 바로 물어볼 수 있게 하고 싶었는데, 전체 문서를 context로 넘기기엔 양이 제법 많았습니다. 그래서 MCP 서버를 만들기로 했습니다.

MCP(Model Context Protocol)는 LLM이 외부 도구나 데이터에 접근할 수 있게 해주는 프로토콜입니다. MCP 서버를 직접 만들어서 Cursor, Claude Code, Codex가 Decision Records를 검색하고 조회할 수 있게 했습니다.
Kotlin, TypeScript, Python 모두 MCP 서버 구현이 가능합니다. AI Agent를 통해 자연어로 개발할 것이라 언어는 크게 중요하지 않았습니다. 처음엔 익숙한 Kotlin을, 그다음엔 Node.js를 고려했지만, 결국 Python을 선택했습니다. 가볍게 시작할 수 있고, 형태소 분석이나 검색 알고리즘 관련 라이브러리가 잘 갖춰져 있었기 때문입니다.
검색을 구현하는 데는 네 가지 라이브러리를 활용했습니다. python-frontmatter로 markdown 파일의 YAML frontmatter와 마크다운 본문을 분리해서 메타정보를 구조화했고, kiwipiepy로 한국어 형태소 분석을 처리했습니다. 단순 공백 분리로는 조사나 어미가 붙은 경우("결제를", "처리하는")에 검색이 제대로 되지 않기 때문입니다. bm25s는 단순 키워드 포함 여부가 아니라, 해당 단어가 문서 전체에서 얼마나 드물게 쓰이는지와 해당 문서에서 얼마나 자주 등장하는지를 함께 고려해서 관련도 점수를 계산합니다. MCP 프로토콜 구현은 fastmcp로 추상화해서 도구 정의와 입출력 스키마를 직접 구현하지 않아도 되게 했습니다.
각 markdown 파일은 H2 헤더(## 배경, ## 결정 사항 등)를 기준으로 청크(chunk)로 나뉩니다. 너무 짧은 청크는 다음 청크와 병합하고, BM25 검색은 이 청크 단위로 점수를 매깁니다. 검색 결과를 반환할 때는 매칭된 청크만 돌려주는 게 아니라 앞뒤 청크도 함께 포함해서(window), AI가 맥락을 갖고 답할 수 있게 했습니다.
별도 DB나 캐시 서버 없이 메모리에서만 처리합니다. 검색할 때마다 decision-records/ 디렉터리를 스캔하고 메모리에 인덱스를 만든 뒤, 호출이 끝나면 사라지는 방식입니다. 덕분에 docs repository를 pull 하고 MCP 클라이언트 설정 파일에 서버 경로만 추가하면 바로 동작합니다.
실제로 이렇게 쓴다
의사결정 기록과 MCP가 들어있는 docs repository를 pull하고, MCP 클라이언트(Claude Code, Codex, Cursor 등)에 연결하면 됩니다. 이게 끝입니다. "멀티모듈로 분리한 이유가 뭐야?", "구독/결제 정책이 변경된 이유가 뭐야?" 등의 질문은 이제 MCP를 통해서 확인할 수 있습니다.
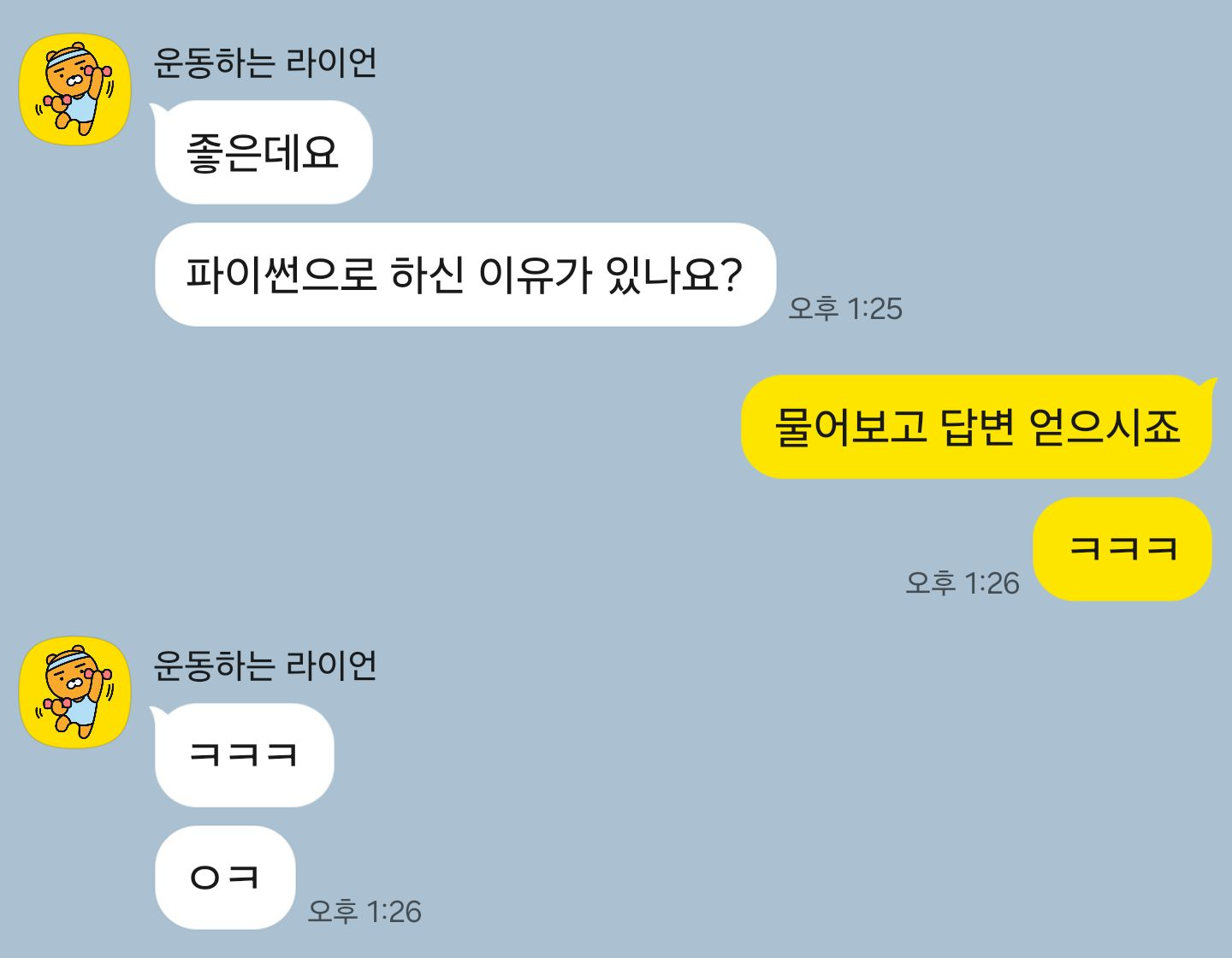
아래는 MCP를 만들고 팀원에게 받은 질문에 대한 답변입니다.

한계 및 개선 방향
현재 구조에는 분명한 한계도 있습니다. BM25는 키워드 기반의 통계적 검색 방식이기 때문에 문장의 의미를 이해하지는 못합니다. 예를 들어 "Paddle"을 검색했을 때 실제로는 "구독 결제"나 "웹훅 처리"와 관련된 문서를 기대하더라도 결과가 잘 나오지 않거나, "왜 모놀리식을 선택했지?"처럼 자연어 질문 형태의 검색에는 상대적으로 약한 모습을 보입니다.
이러한 한계를 보완할 수 있는 방법이 바로 Text Embedding 기반 검색입니다. 키워드가 일치하지 않더라도 의미적으로 연관된 문서를 찾아낼 수 있다는 장점이 있습니다. 다만 외부 API를 사용할 경우 비용이 발생하고, 로컬에서 직접 모델을 운영하려면 모델 파일 용량과 실행 환경에 대한 부담이 생깁니다. 또한 벡터를 사전에 계산하고 저장하기 위한 별도의 저장소가 필요해지면서, 현재의 단순한 구조가 점점 복잡해질 수 있습니다.
현재 규모(문서 약 50개 이하 수준)에서는 BM25만으로도 충분히 실용적인 검색 품질을 확보할 수 있다고 판단했습니다. 향후 문서 수가 수백 개 이상으로 증가하거나, 검색 품질이 실제 문제로 이어지는 시점에 임베딩 기반 검색으로의 전환을 검토하는 것이 더 적절해 보입니다.
마치며
MCP 서버를 처음 만들어보면서, 거창한 인프라 없이도 로컬 환경에서 가볍게 동작하는 검색 도구를 충분히 구축할 수 있다는 점이 인상적이었습니다.
AI Agent 시대에는 코드가 훨씬 빠르게 축적됩니다. 그만큼 "왜 이런 결정을 했는가"에 대한 맥락은 더 빠르게 희석됩니다. 의사결정 과정을 구조적으로 기록해두는 것은 사람뿐 아니라 AI Agent가 작업을 이어받을 때에도 중요한 기반이 됩니다. 이번 작업을 통해 그 필요성을 특히 크게 느낄 수 있었습니다.
참고
- https://toss.tech/article/tosspayments-mcp
- https://norahsakal.com/blog/mcp-vs-api-model-context-protocol-explained
'협업' 카테고리의 다른 글
| Github Branch Rulesets 로 프로젝트 안전하게 관리하기 (1) | 2025.01.14 |
|---|---|
| Git Submodule(서브모듈)을 통해서 Spring 설정(yml) 관리하기 (1) | 2025.01.05 |